
SeaArtには「コントロールネット」という機能があります。
この機能は非常に強力で、SeaArtで画像生成をするならぜひとも使いこなしたい機能なのですが、モードが多く使い方もやや複雑で一見だとなかなかとっつきづらそうでもあります。
なのでこの記事では、まずはコントロールネットの「モードの種類」に焦点を当てて説明します!
初心者の方でも分かりやすいように画像をたくさん使って説明していますので、ぜひ参考にしてみてください!
目次
コントロールネット とは
コントロールネットとは
画像を元にしてモード別にエフェクトをかけ直して再生成する機能のことです。
例えば
- 構図やポーズを同じままにして、人物を変えたい
- 画像はほぼ同じままにして、服の色だけを変えたい
- 同じ人物のベッツポーズや構図の画像を作りたい
という場合に効果を発揮します。
使い方自体はシンプルで、SeaArtの創作モードから「コントロールネット」を選んで設定していくだけです。
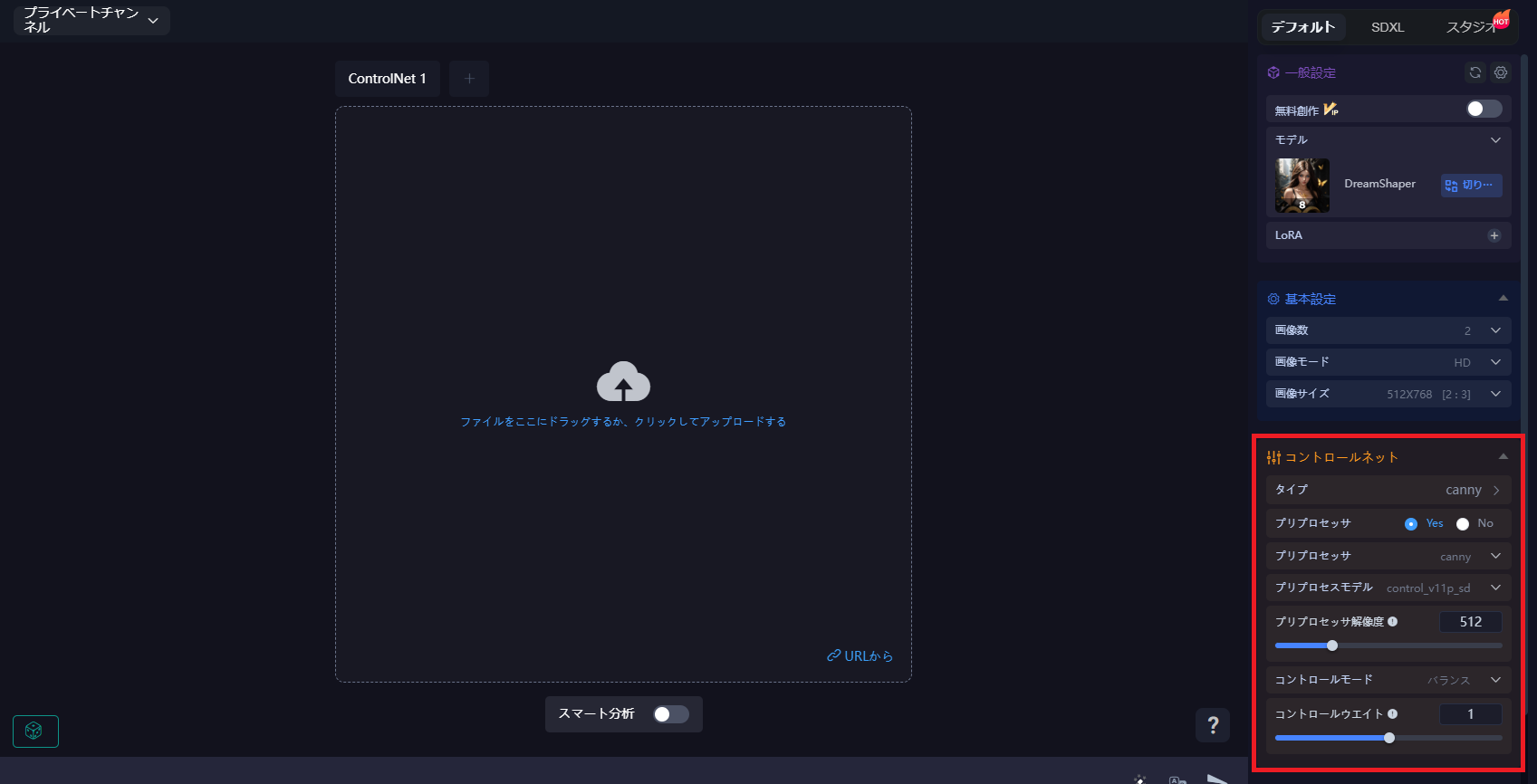
まぁ、その「設定」が難しいのですが......。
コントロールネット の種類
コントロールネットには16種類ものモードがあり、それぞれに特徴があります。

これから、16種類の機能全ての特徴を紹介しますので、ぜひ参考にしてみてください!
openpose full
「openpose full」はコントロールネットの順番的には2番目のモードなのですが、説明の都合で一番最初に説明させていただきます!
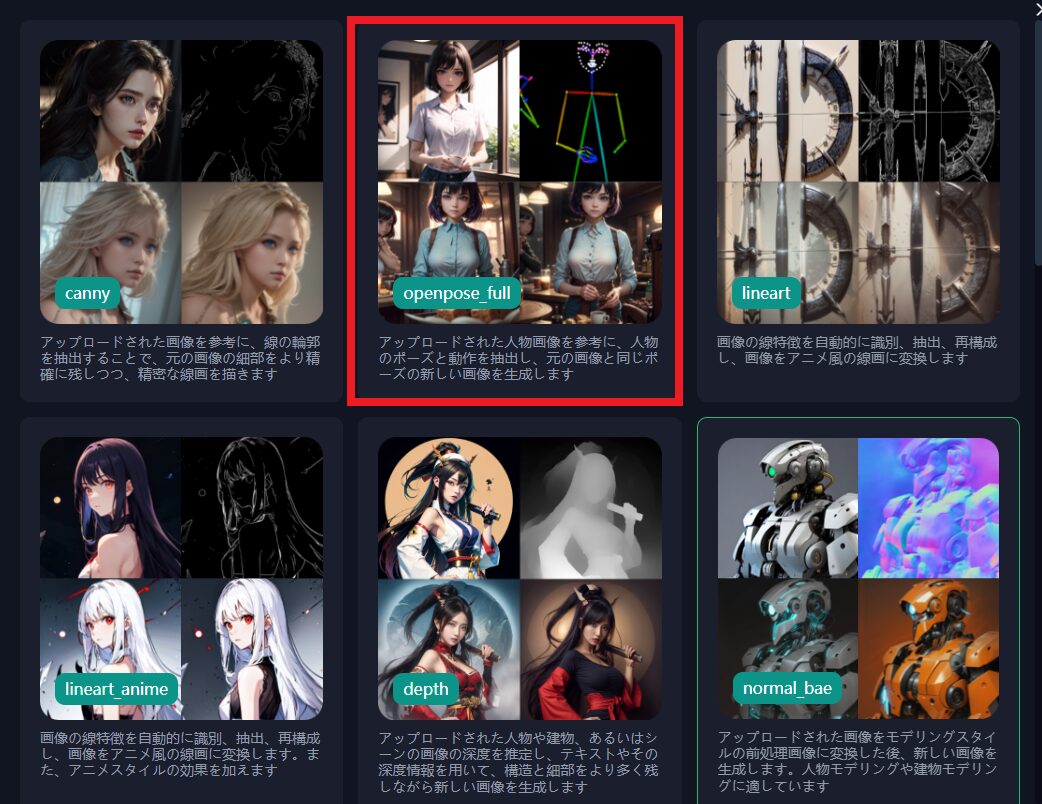
こちらの「openpose full」、読み込んだ画像から人物のポーズのみを抽出して、新たに画像を生成します。

その性質上、ポージングソフトやポーズ集などとは相性が抜群です!

ソフトやポーズ集に「AI画像への使用禁止」などが無いかは要チェックです。
↓の「easy pose」で作ったポージング画像を読み込みます。

生成中......
すごい! これでもうポーズの修正で困らなくて済むぞ!
実際、AI画像生成で特に難しいのが「ポーズを決める」ことだと思うので、この「openpose full」はコントロールネットの中でも特に重要でしょう。
canny
賢い(canny)という意味のこのモードでは、画像から輪郭線を抽出し、そこに描写を加えて再生成します。

使用するのは、先ほど生成した↓の画像です。

プロンプトには「,」とだけ打ちます。
プロンプトに「,」とだけ入力すると、AIは「指示なし」と判断して(多分)AIの性癖のままに書き始めます。
生成中......


画像のポーズや背景の大体の形は維持しつつ、新しい画像として生成されました。
「輪郭線を抽出」なので、輪郭線の内側部分はAIによる再描写がされている感じですね。


これのcannyは、気に入った画像と同じ構図で別の雰囲気を持つ画像を作りたい時などに使えます。
描写を追加する傾向にあるので、「そのままが良いという方は」、後述のlineartの方がおススメです。
lineart
先ほどの「canny」と似ているのですが、こちらの「lineart」は「輪郭線だけではない線画を抽出する」という特徴があります。

「canny」は輪郭線の内側は結構AIによって変更されますが、「lineart」は輪郭線の内側の線まで抽出するので、より元の画像に忠実に画像を再生成します。
再生成する画像・プロンプトは先ほどと同じです。
生成中......


「lineart」の方が、筋肉の付き方などが元の画像に近いですね。
lineart anime
line artをさらにアニメ調にして再生成するのが「lineart anime」です。
今までと同じ画像・プロンプトで再生成します。
生成中......


大分アニメ調になりましたね。
特に設定や調整をしていないので大分粗いですが、ポーズや筋肉の付き方はかなり元の画像に忠実になっています。
depth
こちらは画像から深度を抽出して再生成するモードです。
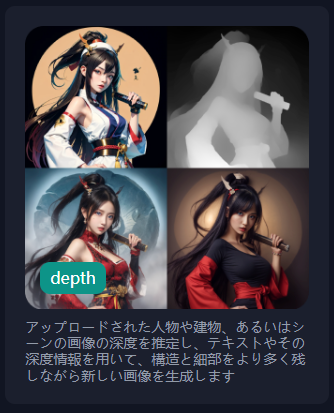
↑の説明だけでは何を言っているのか分かりづらいですが、元の画像を↓のようなあいまいな輪郭のみの状態にして、そこから画像を再生成します。

「ポーズや構図は変えたくない。だけど人物や建物は思いっきり変更したい」
そんな時にはこちらの「depth」がおススメです。
ここだけ聞くと
「それってcannyで良いんじゃないの?」
そう思われるかもしれませんが、cannyと違って輪郭線の内側に線が無いので、cannyよりも大胆に再生成することができます。
それでは再生成していきます。
生成中......


ガラリと変わりましたね。
cannyの方とも比べてみましょう。
cannyよりも、服装や筋肉の付き具合が元の画像より離れているのが分かります。
normal_bae
こちらは先述の「depth」と近いのですが、depthがグレーの曖昧な輪郭だったのに対してこちらは「法線マップ」という3Dモデリングなどで良く使われるテクスチャを用います。

......ただ、ぶっちゃけdepthとの違いがあまりわからず
depthで良いんじゃね?
となりがちです。
ただ、凹凸を表現できる法線マップを使用しているということで、立体感のある画像の生成にはこっちの方が向いている......のかなぁ?
なんだかぼやけた解説になってしまいましたが、とりあえず生成した画像を見ていきましょう。
生成中......


depthとも比べてみましょう。
segmentation
「segmentation」は区分・区分け・細分化という意味です。
読み込んだ画像の要素()
なので、コントロールネットの中でも結構元画像の形を変えちゃう方です。

ちなみにこちら「ユーザーから提供された画面の説明に基づいて~」とある通り、プロンプトを入力しないと元の画像と全く関係ない画像が生成されてしまうので注意です。

試しにプロンプト無しで生成してみましょう。
生成中......


何があった?
ってぐらい変わりますね。
では、ちゃんとプロンプトを打ちこんで生成します。
生成中......


構図が大きく変わりましたね。
イメージとしては
元の画像をAIにパーツとして渡しつつ、プロンプトで再構築してもらう感じ
でしょうか。
間違っていたらごめんなさい......。
超高画質の再描写
こちらは画像の細部を精細に描写して、画質や解像度を上げるモードです。

いつもの設定で生成していきましょう。
生成中......


確かに、のっぺりしていてた背景の書き込みが飛躍的に向上しています。


ただし元から高密度に書き込まれていた人物に顕著な変化はなく、あくまでも「書き込みが少なく、精細でなかった部分を向上させる」モードかもしれません。
ちなみに画像サイズなどに変化はありません。

元画像

mlsd
直線を検知して再描写します。
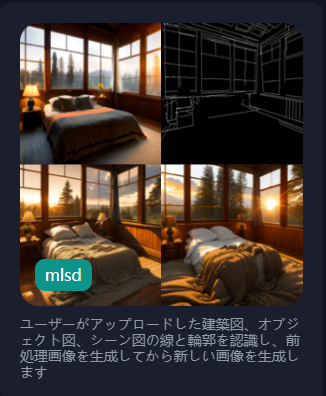
人体などには直線が少ないのでほとんど無視して再描写されますが、建物や家具などを元の画像の雰囲気を残したまま再描写する際には有効です。
生成しましょう。
生成中......




まー別物ですね。
ただ、背景の建物に名残が感じられたりと、やはり建築物系には強いモードだと分かります。
ちなみにプロンプトをちゃんと入れると、ちゃんとした画像が生成されます。
生成中......


scribble_hed
画像から線を抽出して再生成します。
ちらは「canny」や「lineart」とよく似ていますが、それらと違って線の太さが太いです。

線が太い=細やさに欠ける=元画像の再現度が低い
ということです。
生成中......


大分、元の画像からかけ離れてしまいましたね。
このままだと「canny、lineartで良いじゃん」となりがちですが、この「scribble_hed」には他のモードでは担えない役割があります。
それは自分が雑に描いた絵をもとにして生成させる
ということです。
どういうことかと言いますと、「canny」や「lineart」はある程度精密な元画像が無いと、まともに線や輪郭を抽出できません。
しかし精密さのない太い線でも拾ってくれる「scribble_hed」なら、絵が得意でない人が描いた絵でも、線や輪郭として抽出してくれるのです。
以下がその例です。

生成中......

今回は筆者があまりにも雑すぎましたが、もうちょっとちゃんと書けば、生成される画像の精度も上がります。
線はもっと太めが良いかも。
ある程度絵が描ける方におススメしたいモードですね。
hed_safe
こちらは元の画像から輪郭を抽出し、それをもとに高画質な線画を生成します。

ただしこちらはプロンプトを書かないとAIが輪郭を自由に解釈しすぎてしまうようなので注意が必要です。
生成中......


AIが何を見ているのかさっぱりわかりませんが、こちらのモードでプロンプト無しは推奨できなさそうです。
生成中......


プロンプトを入力すれば、ちゃんとした画像を生成してくれます。
color_grid
こちらはまだ日本語翻訳されていませんが、読み込んだ画像の色情報を抽出して画像を生成します。
今までは線を抽出してきましたが、このモードには明確な形の指定が無いので、AIが比較的自由に各モードです。

生成中......


何か細長いですが、これも「色情報だけを抽出」という元画像との関連の薄さからでしょう。
shuffle
画像から抽出した情報(要素)をランダムに組み合わせて、新しい画像として生成するモードです。

AIの裁量が大きいモードですね。
生成中......


元の画像からは大分変りましたね。
ガチャ感覚でこのモードを使うのも面白いかも?
参考生成
読み込んだ画像のキャラクター・物品などを保ちつつ、新しい画像にします。

生成中......


確かに、服や肌色などにかなり元の面影を感じますので、しっかり設定してあげれば元の画像の人物を再現して別の構図の画像を作れそうです。
recolor
これは元の画像を維持しつつ、部分的に色を変えるモードです。

今回は、下着の色を黒から赤に変えてみます。
生成中......

しっかり赤い色に変わりました!
「バリエーション」などで塗って指定するよりも楽だし精度も高そうです。

ip adapter
こちらはかなり独特なモードで、画像をプロンプトとして使います
例えば
「canny」で輪郭線を抽出して、そこに「ip_adapter」で他の画像から抽出した要素を足して再生成します。
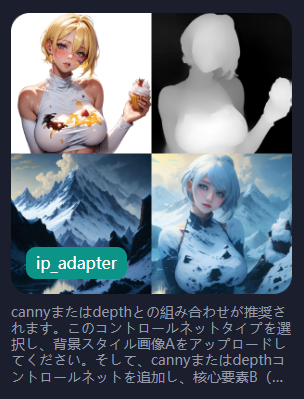
言葉だけでは分かりづらいと思いますので、実際に作業していきます。
「ip_adapter」では、コントロールネットを2つ使います。
まずはメインにしたい画像を選びます。
この時、推奨されているのは「canny」か「depth」です。
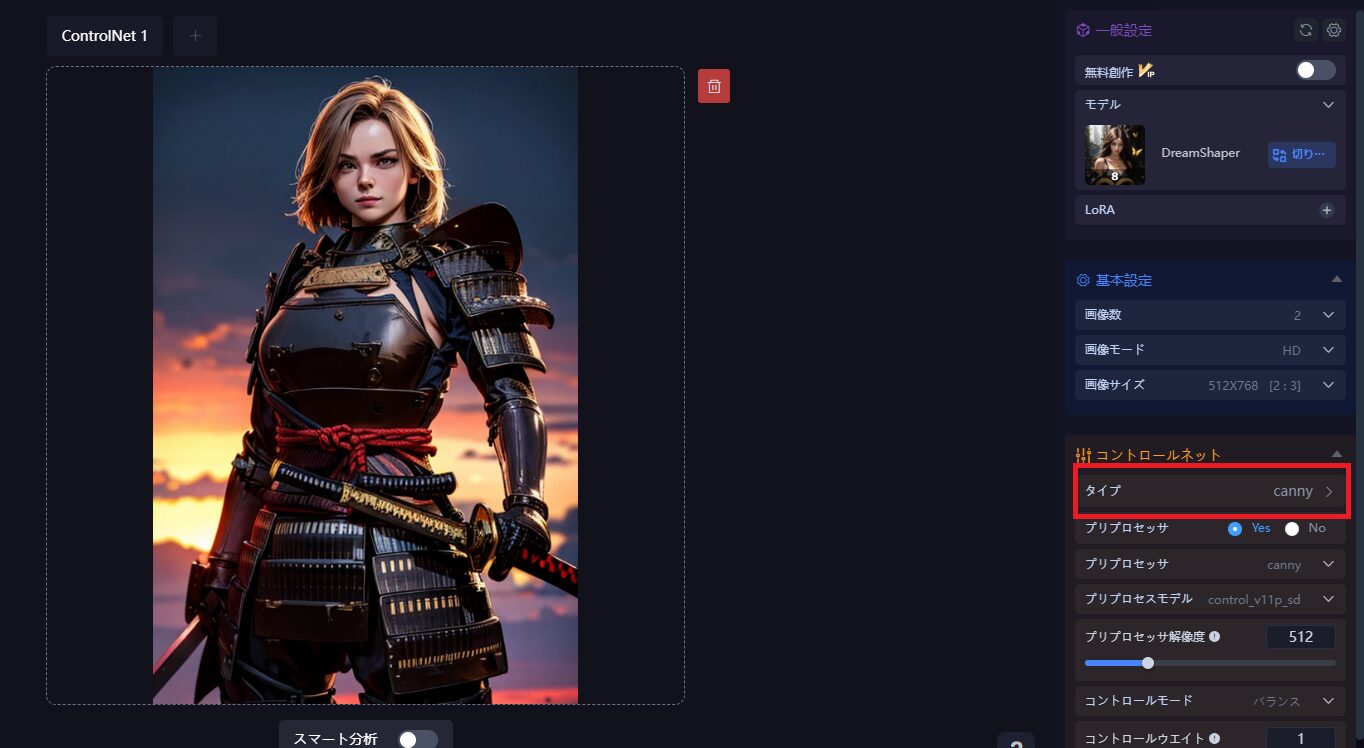
そして「+」を押して、コントロールネットを増やします。
「画像プロンプト」として使いたい画像を選択し「ip_adapter」にします。
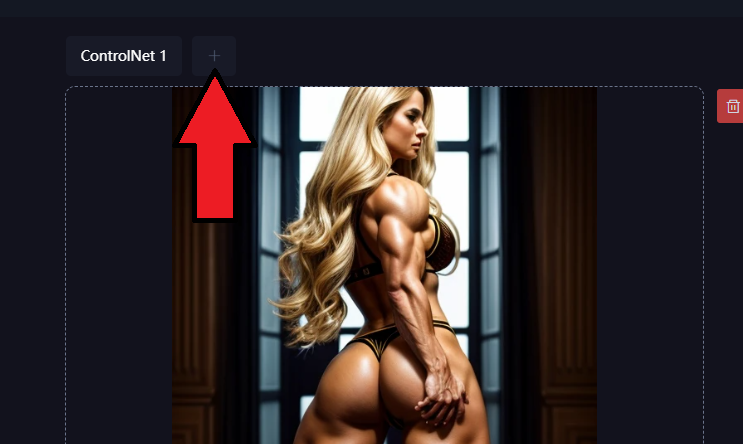
そして生成します。
生成中......


どうでしょう
構図やポーズは「canny」の画像、画像の要素は「ip_adapter」の画像
というものが生成されたのではないでしょうか?

目的別おススメモード
ここまで計16モードを紹介してきましたが「自分の生成したい画像はどのモードで作れそうか」というのは、ぱっと見分かりづらいのではないでしょうか?
なので、筆者が思う用途別おススメモードを紹介いたします!
AI画像生成初級者の感想であることは、あらかじめ了承くださいませ。
構図やポーズを維持したまま再生成したい
- 【canny】......輪郭線を抽出して再生成
- 【openpose_full】......人物のポーズのみを抽出したい場合に
- 【lineart】......線画を抽出する。cannyよりも元の画像に忠実
- 【lineart_anime】......lineartと同じく線画を抽出して、アニメ風の画像に生成する
- 【depth】......「canny」や「line art」と近いが、こちらは輪郭線の内側はがっつり変える
- 【normal_bae】......「depth」に近い。depthより立体感が出るのかも?
- 【mlsd】......元の画像の直線を抽出して再生成する。人物などの線はほぼ拾わないが、建築物などを再生成するときに
- 【超高画質の再描写】......元の画像のままに高精細に再生成
- 【scrible_hed】......画像を太い線画にして再生成。手書きの大雑把なラフ画から生成したい場合に。
- 【hed_safe】......画像の輪郭線を抽出。「canny」よりも粗い?
- 【ip_adapter】......画像をプロンプトとして扱い、他の画像にその要素を混ぜる。
構図やポーズも変えたい(AIによる変化の度合いが強い)
- 【segmentaition】......人物や建物の場所は同じだが、ポーズや見た目が大きく変わる。
- 【color_grid】......色情報のみを抽出。カラーリング以外が大きく変わる
- 【shuffle】......画像から要素を抽出して、ランダムに組み合わせて再生成
- 【参考生成】......元の画像に描かれている人物や物の特徴を維持しつつ再生成

